XGBoost integration guide#
![]()
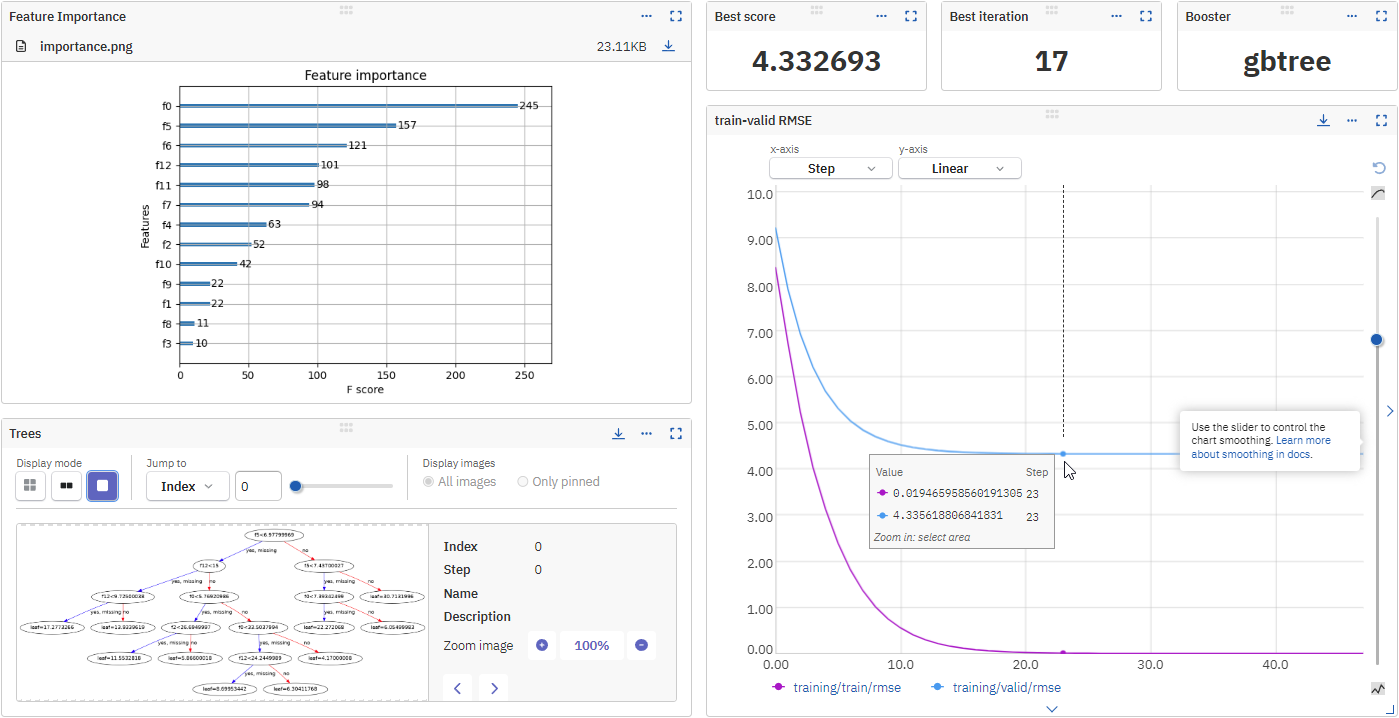
XGBoost is an optimized distributed library that implements machine learning algorithms under the Gradient Boosting framework. With the Neptune-XGBoost integration, the following metadata is logged automatically:
- Metrics
- Parameters
- The pickled model
- The feature importance chart
- Visualized trees
- Hardware consumption metrics
- stdout and stderr streams
- Training code and Git information
Before you start#
- Sign up at neptune.ai/register.
- Create a project for storing your metadata.
-
Ensure that you have at least version 1.3.0 of XGBoost installed:
Installing the integration#
To use your preinstalled version of Neptune together with the integration:
To install both Neptune and the integration:
Passing your Neptune credentials
Once you've signed up and created a project, set your Neptune API token and full project name to the NEPTUNE_API_TOKEN and NEPTUNE_PROJECT environment variables, respectively.
To find your API token: In the bottom-left corner of the Neptune app, expand the user menu and select Get my API token.
Your full project name has the form workspace-name/project-name. You can copy it from the project settings: Click the
menu in the top-right →
Details & privacy.
On Windows, navigate to Settings → Edit the system environment variables, or enter the following in Command Prompt: setx SOME_NEPTUNE_VARIABLE 'some-value'
While it's not recommended especially for the API token, you can also pass your credentials in the code when initializing Neptune.
run = neptune.init_run(
project="ml-team/classification", # your full project name here
api_token="h0dHBzOi8aHR0cHM6Lkc78ghs74kl0jvYh...3Kb8", # your API token here
)
For more help, see Set Neptune credentials.
If you want to log visualized trees after training (recommended), additionally install Graphviz:
Note
The above installation is only for the pure Python interface to the Graphviz software. You need to install Graphviz separately.
For installation help, see the Graphviz documentation .
If you'd rather follow the guide without any setup, you can run the example in Colab .
XGBoost logging example#
This example walks you through logging metadata as you train your model with XGBoost.
You can log metadata during training with NeptuneCallback.
Logging metadata during training#
-
Start a run:
-
If you haven't set up your credentials, you can log anonymously:
-
-
Initialize the Neptune callback:
-
Prepare your data, parameters, and so on.
-
Pass the callback to the
train()function and train the model: -
To stop the connection to Neptune and sync all data, call the
stop()method: -
Run your script as you normally would.
To open the run, click the Neptune link that appears in the console output.
Example link: https://app.neptune.ai/common/xgboost-integration/e/XGBOOST-84
Exploring results in Neptune#
In the run view, you can see the logged metadata organized into folder-like namespaces.
| Name | Description |
|---|---|
booster_config |
All parameters for the booster. |
early_stopping |
best_score and best_iteration (logged if early stopping was activated) |
epoch |
Epochs (visualized as a chart from first to last epoch). |
learning_rate |
Learning rate visualized as a chart. |
pickled_model |
Trained model logged as a pickled file. |
plots |
Feature importance and visualized trees. |
train |
Training metrics. |
valid |
Validation metrics. |
More options#
Changing the base namespace#
By default, the metadata is logged under the namespace training.
You can change the namespace when creating the Neptune callback:
Using Neptune callback with CV function#
You can use NeptuneCallback in the xgboost.cv function. Neptune will log additional metadata for each fold in CV.
Pass the Neptune callback to the callbacks argument of lgb.cv():
import neptune
from neptune.integrations.xgboost import NeptuneCallback
# Create run
run = neptune.init_run()
# Create neptune callback
neptune_callback = NeptuneCallback(run=run, log_tree=[0, 1, 2, 3])
# Prepare data, params, etc.
...
# Run cross validation and log metadata to the run in Neptune
xgb.cv(
params=model_params,
dtrain=dtrain,
callbacks=[neptune_callback],
)
# Stop run
run.stop()
import neptune
import xgboost as xgb
from neptune.integrations.xgboost import NeptuneCallback
from sklearn.datasets import load_california_housing
from sklearn.model_selection import train_test_split
# Create run
run = neptune.init_run(
api_token=neptune.ANONYMOUS_API_TOKEN, # (1)!
project="common/xgboost-integration", # (2)!
name="xgb-cv", # optional
tags=["xgb-integration", "cv"], # optional
)
# Create Neptune callback
neptune_callback = NeptuneCallback(run=run, log_tree=[0, 1, 2, 3])
# Prepare data
X, y = load_california_housing(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=123,
)
dtrain = xgb.DMatrix(X_train, label=y_train)
dval = xgb.DMatrix(X_test, label=y_test)
# Define parameters
model_params = {
"eta": 0.7,
"gamma": 0.001,
"max_depth": 9,
"objective": "reg:squarederror",
"eval_metric": ["mae", "rmse"]
}
evals = [(dtrain, "train"), (dval, "valid")]
num_round = 57
# Run cross validation and log metadata to the run in Neptune
xgb.cv(
params=model_params,
dtrain=dtrain,
num_boost_round=num_round,
nfold=7,
callbacks=[neptune_callback],
)
# Stop run
run.stop()
-
The
api_tokenargument is included to enable anonymous logging.Once you've registered, leave the token out of your script and instead save it as an environment variable.
-
Projects in the
commonworkspace are public and can be used for testing.To log to your own workspace, pass the full name of your Neptune project:
workspace-name/project-name. For example,project="ml-team/classification".You can copy the name from the project details ( → Details & privacy).
In the All metadata section of the run view, you can see a fold_n namespace for each fold in an n-fold CV:
Namespaces inside the fold_n namespace:
| Name | Description |
|---|---|
booster_config |
All parameters for the booster. |
pickled_model |
Trained model logged as a pickled file. |
plots |
Feature importance and visualized trees. |
Working with scikit-learn API#
You can use NeptuneCallback in the scikit-learn API of XGBoost.
Pass the Neptune callback while creating the regressor object:
import neptune
from neptune.integrations.xgboost import NeptuneCallback
# Create run
run = neptune.init_run()
# Create neptune callback
neptune_callback = NeptuneCallback(run=run)
# Prepare data, params, etc.
X_train = ...
y_train = ...
model_params = {...}
# Create regressor object and pass the Neptune callback
reg = xgb.XGBRegressor(**model_params, callbacks=[neptune_callback])
# Fit the model
reg.fit(X_train, y_train)
# Stop run
run.stop()
import neptune
import xgboost as xgb
from neptune.integrations.xgboost import NeptuneCallback
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
# Create run
run = neptune.init_run(
api_token=neptune.ANONYMOUS_API_TOKEN, # (1)!
project="common/xgboost-integration", # (2)!
)
# Create neptune callback
neptune_callback = NeptuneCallback(run=run)
# Prepare data
data = fetch_california_housing()
y = data["target"]
X = data["data"]
X_train, X_test, y_train, y_test = train_test_split(X, y)
# Create regressor object and pass the Neptune callback
reg = xgb.XGBRegressor(callbacks=[neptune_callback])
# Fit the model
reg.fit(X_train, y_train)
# Stop run
run.stop()
-
The
api_tokenargument is included to enable anonymous logging.Once you've registered, leave the token out of your script and instead save it as an environment variable.
-
Projects in the
commonworkspace are public and can be used for testing.To log to your own workspace, pass the full name of your Neptune project:
workspace-name/project-name. For example,project="ml-team/classification".You can copy the name from the project details ( → Details & privacy).
Manually logging metadata#
If you have other types of metadata that are not covered in this guide, you can still log them using the Neptune client library.
When you initialize the run, you get a run object, to which you can assign different types of metadata in a structure of your own choosing.
import neptune
# Create a new Neptune run
run = neptune.init_run()
# Log metrics inside loops
for epoch in range(n_epochs):
# Your training loop
run["train/epoch/loss"].append(loss) # Each append() call appends a value
run["train/epoch/accuracy"].append(acc)
# Track artifact versions and metadata
run["train/images"].track_files("./datasets/images")
# Upload entire files
run["test/preds"].upload("path/to/test_preds.csv")
# Log text or other metadata, in a structure of your choosing
run["tokenizer"] = "regexp_tokenize"
Related
- Add Neptune to your code
- What you can log and display
- Resume a run
- API reference ≫ XGBoost integration
- neptune-xgboost repo on GitHub
- XGBoost on GitHub